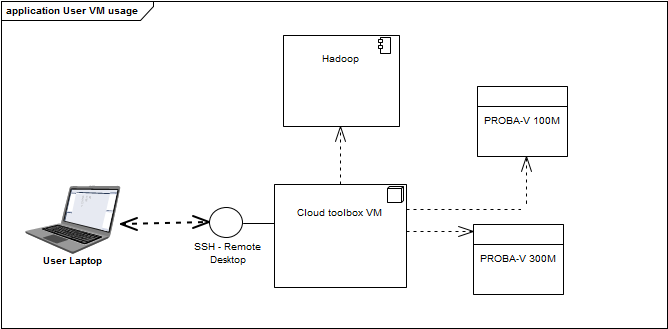
To speed up processing, it is often desirable to distribute the work over a number of machines. The easiest way to do this is to use the Apache Spark processing framework. The fastest way to get started, is to read the Spark documentation: https://spark.apache.org/docs/2.3.3/quick-start.html.
The Spark version installed on our cluster is 2.3.3 so it is recommended that you stick with this version. It is however not impossible to use a newer version if really needed. Spark is also installed on your virtual machine, so you can run 'spark-submit' from the command line after setting the following 2 environment variables:
export SPARK_MAJOR_VERSION=2
export SPARK_HOME=/usr/hdp/current/spark2-client
To run jobs on the Hadoop cluster, the 'cluster' deploy-mode has to be used, and you need to authenticate with Kerberos. For the authentication, just run 'kinit' on the command line. You will be asked to provide your password. Two other useful commands are 'klist' to show whether you have been authenticated, and 'kdestroy' to clear all authentication information. After some time, your login will expire, so you'll need to run 'kinit' again.
A Python Spark example is available which should help you to get started.
Resource management
Spark jobs are being run on a shared processing cluster. The cluster will divide available resources among all running jobs, based on certain parameters.
Memory
To allocate memory to your executors, there are two relevant settings:
The amount of memory available for the Spark 'Java' process: --executor-memory 1G
The amount of memory for your Python or R script: --conf spark.yarn.executor.memoryOverhead=2048
If you need more detailed tuning of the memory managment inside the Java process, you can use: --conf spark.memory.fraction=0.05
Number of parallel jobs
The number of tasks that are processed in parallel can be determined dynamically by spark. Therefore you should use these parameters:
--conf spark.shuffle.service.enabled=true --conf spark.dynamicAllocation.enabled=true
Optionally, you can set upper or lower bounds:
--conf spark.dynamicAllocation.maxExecutors=30 --conf spark.dynamicAllocation.minExecutors=10
If you want a fixed number of executors, use:
--num-executors 10
We don't recommend this, as it reduces the ability of the cluster manager to optimally allocate resources.
Dependencies
A lot of commonly used Python dependencies are preinstalled on the cluster, but in some cases, you want to provide your own.
The first thing you need to do this, is to get a package containing your dependency. PySpark supports zip, egg, or whl packages. The easiest way to get such a package is by using pip:
pip download Flask==1.0.2
This will download the package, and all of its dependencies. Pip will prefer to download a wheel if one is available, but may also return a ".tar.gz" file, which you will need to repackage as zip or wheel.
To repackage a tar.gz as wheel:
tar xzvf package.tar.gz
cd package
python setup.py bdist_wheel
Note that a wheel may contain files that are dependent on the version of Python that you are using, so make sure you use the right (2.7 or 3.5) Python to perform this command.
Once the wheel is available, you can include it in your spark-submit command:
--py-files mypackage.whl
Notifications
If you want to receive a notification (e.g. an email) when the job reaches a final state (succeeded or failed), you can add a SparkListener on the SparkContext for Java or Scala jobs:
SparkContext sc = ... sc.addSparkListener( new SparkListener() { ... @Override public void onApplicationEnd(SparkListenerApplicationEnd applicationEnd) { // send email } ... });
You can also implement a SparkListener and specify the classname when submitting the Spark job:
spark-submit --conf spark.extraListeners=path.to.MySparkListener ...
In PySpark, this is a bit more complicated as you will need to use Py4J:
class PythonSparkListener(object): def onApplicationEnd(self, applicationEnd): // send email # also implement other onXXX methods class Java: implements = ["org.apache.spark.scheduler.SparkListener"]
sc = SparkContext() sc._gateway.start_callback_server() listener = PythonSparkListener() sc._jsc.sc().addSparkListener(listener) try: # your Spark logic goes here ... finally: sc._gateway.shutdown_callback_server() sc.stop()
In a future release of the JobControl dashboard, we will add the possibility to send an email automatically when the job reaches a final state.